Introducción
En el mundo en constante evolución de la inteligencia artificial, el aprendizaje por refuerzo (RL) se destaca como un método poderoso para enseñar a los agentes a tomar decisiones en entornos complejos. Uno de los desafíos más interesantes de RL es el entorno de carreras de autos de Gymnasium, una tarea de control continuo que requiere que los agentes naveguen por una pista de carreras de manera eficiente. Este entorno plantea desafíos únicos, como los espacios de observación de gran dimensión y la necesidad de acciones de control precisas.
En esta entrada del blog, nos sumergimos en el emocionante proceso de resolver el entorno de las carreras de coches utilizando tres importantes algoritmos de RL: Soft Actor-Critic (SAC), Proximal Policy Optimization (PPO) y Deep Q-Network (DQN). Cada uno de estos algoritmos tiene sus propias fortalezas y debilidades, lo que los convierte en candidatos ideales para un estudio comparativo.
Exploraremos los fundamentos teóricos de cada algoritmo, analizaremos su implementación y analizaremos su desempeño en el entorno de las carreras de autos. Al final de este recorrido, conocerás los matices de cada enfoque y comprenderás cómo abordan los desafíos que plantean los espacios de acción continua y los entornos dinámicos. Tanto si eres un experto en aprendizaje automático como si eres un principiante curioso, esta exploración promete profundizar tu comprensión del aprendizaje por refuerzo y su aplicación a tareas de control complejas.
Entorno y recompensa de carreras de coches
El entorno CarRacing-v3 de Gymnasium es una tarea de control continuo en la que el agente controla un automóvil en una pista de carreras generada por procedimientos. El objetivo es conducir el coche por la pista de la forma más eficiente posible, minimizando el tiempo que pasa fuera de la pista y maximizando el número de fichas cubiertas. El entorno presenta un problema difícil debido a su estado continuo y a sus espacios de acción, que requieren un control preciso para evitar salirse de la pista.
El sistema de recompensas de Carracing-v3 incentiva principalmente al agente a permanecer en la pista al otorgar recompensas positivas proporcionales a la cantidad de fichas de pista que cubre. La recompensa típica de cada ficha es +1000/N, donde N es el número total de fichas. Si el coche se sale de la pista, el agente deja de recibir recompensas positivas, lo que penaliza indirectamente el comportamiento. El episodio termina si el coche pasa demasiado tiempo fuera de la pista o cubre con éxito todas las fichas de la pista. Esta estructura de recompensas anima al agente a conducir sin problemas, evitar perder tiempo fuera de la pista y maximizar la cobertura de la pista.
Optimización de políticas proximales (PPO)
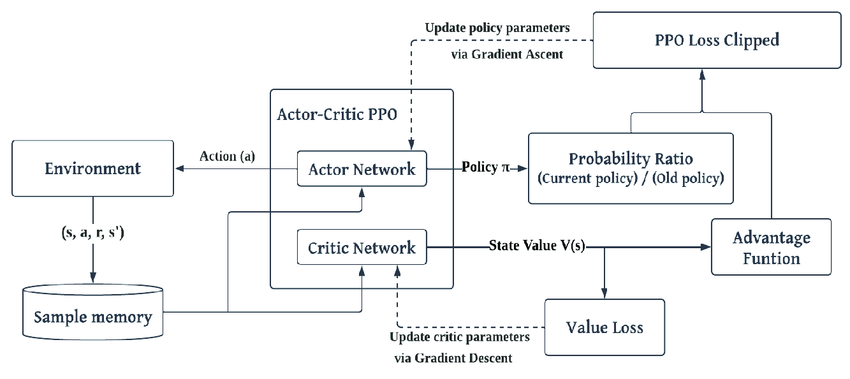
El PPO es un algoritmo basado en políticas que simplifica la optimización de la región de confianza utilizada en algoritmos como TRPO. Es particularmente conocido por su estabilidad y robustez en entornos con espacios de acción continuos.
Implementación:
1import gymnasium as gym
2from stable_baselines3 import PPO
3
4# Create CarRacing environment
5env = gym.make('CarRacing-v3')
6
7# Initialize PPOmodel = PPO('CnnPolicy', env, verbose=1)
8
9# Train the model
10model.learn(total_timesteps=1000000)
11
12# Save the model
13model.save("ppo_car_racing")Rendimiento en carreras de coches:
- Puntos fuertes: El PPO funciona bien en entornos de acción continua, como las carreras de coches, debido a su capacidad para ajustar las políticas de forma gradual, evitando cambios drásticos que podrían desestabilizar el entrenamiento.
- Debilidades: Al ser un algoritmo basado en políticas, el PPO puede requerir más datos en comparación con los métodos fuera de la política, como el SAC, lo que hace que sea menos eficiente en la toma de muestras.
La PPO en la práctica:
En las carreras de coches, el PPO equilibra eficazmente la exploración y la explotación. El mecanismo de recorte de la PPO evita grandes actualizaciones de las políticas, lo que la convierte en una opción fiable para entornos en los que el control debe ser fluido y constante.
Actor-Crítico Suave (SAC)
El SAC es un algoritmo ajeno a la política que utiliza tanto la maximización de la entropía como el marco actor-crítico, y promueve la exploración al alentar al agente a actuar de la manera más aleatoria posible mientras aprende.
Implementación:
1import gymnasium as gym
2from stable_baselines3 import SAC
3
4# Create CarRacing environment
5env = gym.make('CarRacing-v3')
6
7# Initialize SAC
8model = SAC('CnnPolicy', env, verbose=1)
9
10# Train the model
11model.learn(total_timesteps=1000000)
12
13# Save the model
14model.save("sac_car_racing")Rendimiento en carreras de coches:
- Puntos fuertes: El SAC es muy eficiente en la toma de muestras, lo que lo hace adecuado para entornos como las carreras de coches, donde las acciones son continuas y es necesario un control preciso.
- Debilidades: El algoritmo es más complejo de implementar y requiere un ajuste cuidadoso, en particular del parámetro de temperatura, que equilibra la exploración y la explotación.
El SAC en la práctica:
En el entorno de las carreras de coches, la exploración basada en la entropía de SAC ayuda al agente a descubrir una variedad de estrategias y a adaptarse a los cambios en la pista, lo cual es fundamental para navegar por espacios complejos y de gran dimensión.
Red Q profunda (DQN)
DQN es un algoritmo pionero en el dominio RL, particularmente efectivo en espacios de acción discretos. Utiliza una red neuronal para aproximar los valores Q para la estimación del valor de acción.
Implementación:
1import gymnasium as gym
2from stable_baselines3 import DQN
3
4# Create CarRacing environment
5env = gym.make('CarRacing-v3')
6
7# Initialize DQN
8model = DQN('CnnPolicy', env, verbose=1)
9
10# Train the model
11model.learn(total_timesteps=1000000)
12
13# Save the model
14model.save("dqn_car_racing")Rendimiento en carreras de coches:
- Puntos fuertes: El DQN es simple y efectivo en entornos con acciones discretas, con demandas computacionales relativamente bajas.
- Debilidades: Es menos adecuado para espacios de acción continua como las carreras de coches. La necesidad de discretizar las acciones puede llevar a políticas subóptimas y a una reducción del rendimiento.
DQN en la práctica:
Si bien DQN ha tenido éxito en juegos como Atari, su rendimiento en las carreras de coches es limitado debido a la naturaleza continua del entorno. Las modificaciones, como la discretización del espacio de acción o los enfoques híbridos, son necesarias, pero a menudo conducen a resultados menos óptimos.
Comparación de algoritmos
POP:
- Puntos fuertes: Es estable y funciona bien en entornos con espacios de acción continuos debido a su enfoque de gradiente de políticas.
- Debilidades: Como algoritmo basado en políticas, puede ser menos eficiente con las muestras y requerir más interacciones con el entorno.
BOLSA:
- Puntos fuertes: Altamente eficiente en la toma de muestras y sobresale en espacios de acción continua. El uso de la maximización de la entropía conduce a una exploración sólida.
- Debilidades: Más complejo de implementar y ajustar, especialmente con respecto al coeficiente de entropía.
DQN:
- Puntos fuertes: Simplicidad y eficacia en entornos de acción discretos. Es menos intensivo desde el punto de vista computacional que algunos métodos basados en políticas.
- Debilidades: Luchas en espacios de acción continua y de alta dimensión sin modificaciones significativas.
Conclusiones
Para el entorno de CarRacing, que tiene un espacio de acción continuo, PPO y SAC son opciones más eficaces. La eficiencia de toma de muestras y el sólido rendimiento de SAC en entornos de acción continua lo hacen particularmente ventajoso. Por otro lado, el DQN, aunque potente en espacios de acción discretos, es menos adecuado para este entorno debido a sus limitaciones de diseño inherentes.
En resumen, comprender las fortalezas y debilidades de estos algoritmos proporciona información valiosa sobre su aplicabilidad a tareas complejas como las carreras de autos. Al seleccionar y ajustar cuidadosamente el algoritmo correcto, podemos mejorar significativamente el desempeño de un agente en entornos desafiantes.
%2520(1).gif)
Materiales de aprendizaje adicionales
- Aplicación de una red Deep Q para el juego de carreras de coches de OpenAI
- Controle el entorno CarTracing-v2 con DQN desde cero
- Documentación del gimnasio - Carreras de coches
- Resolver las carreras de coches con la optimización de políticas proximales
Repositorio de código y modelos


