소개
강화 학습은 머신 러닝의 학제 간 영역으로, 다음과 같은 게임 분야의 최근 성과로 인해 지난 10년 동안 인기를 얻었습니다. 가기 및 다음과 같은 실제 애플리케이션 자율 주행 자동차.이러한 성장은 최신 GPU의 급속한 발전과 머신 러닝 기술의 발전과도 일치합니다.우리는 컴퓨터 게임에서 기계가 인간을 쉽게 능가할 수 있는 단계에 도달했습니다.Deep Q-Network (DQN) 는 차원이 크고 장기 계획이 필요하기 때문에 아타리와 같은 비디오 게임을 처리하는 데 큰 가능성을 보여주는 새로운 강화 학습 알고리즘입니다.이 튜토리얼에서는 DQN이 어떻게 작동하는지 설명하고 이전에 OpenAI에서 관리하던 체육관의 달 착륙선을 능가하는 데 DQN이 얼마나 효과적인지 보여줍니다.
강화 학습이란 무엇입니까?
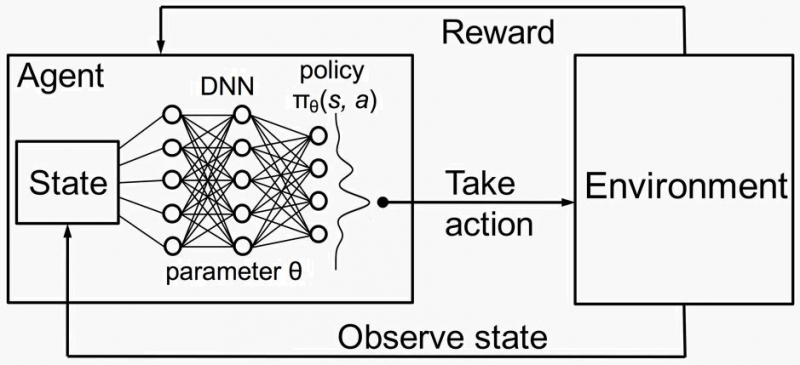
강화 학습은 에이전트가 누적 보상을 극대화하기 위해 환경에서 작업을 수행하여 결정을 내리는 것을 포함합니다.RL의 주요 구성 요소는 다음과 같습니다.
- 대리인: 환경과 상호 작용하는 의사 결정자.
- 환경: 에이전트가 상호 작용하는 외부 시스템입니다.
- 주 (S): 환경의 현재 상황 또는 구성입니다.
- 액션 (A): 상담원이 내릴 수 있는 가능한 조치 또는 결정.
- 보상 (R): 행동의 질을 나타내는 환경으로부터의 피드백.
- 정책 (π): 에이전트의 행동을 정의하는 조치에 상태를 매핑하는 전략입니다.
- 값 함수 (V): 주어진 주에서 예상되는 누적 보상을 추정합니다.
- Q-기능 (Q): 특정 상태에서 특정 조치를 취했을 때 예상되는 누적 보상을 추정합니다.
강화 학습의 작동 원리
- 초기화: 에이전트는 환경에 대한 지식이 전혀 없거나 거의 없는 상태에서 시작합니다.
- 인터랙션: 에이전트는 정책에 따라 조치를 취하여 환경과 상호 작용합니다.
- 피드백: 환경은 각 행동에 새로운 상태와 보상으로 반응합니다.
- 학습: 에이전트는 향후 의사 결정을 개선하기 위해 받은 보상을 기반으로 정책 및/또는 가치 기능을 업데이트합니다.
주요 개념
- 탐사 vs. 착취: 새로운 행동 탐색과 보상이 높은 것으로 알려진 행동 착취의 균형을 맞출 수 있습니다.
- 할인 계수 (γ): 즉각적인 보상과 비교하여 미래 보상의 중요성을 결정합니다.
- 벨만 방정식: 주 가치와 후속 주 가치 간의 관계를 설명합니다.
벨먼 방정식
Bellman 방정식은 가치 함수의 재귀적 분해를 제공하는 강화 학습의 기본 요소입니다.상태 값을 후속 상태 값과 연관시킵니다.Q-함수의 벨만 방정식은 다음과 같이 계산됩니다.
$$ {{Q (s, a) =r+γ\ max_ {a'} Q (s', a')}} $$
여기:
- $ {{Q (s, a)}} $는 상태 sss에서 aaa 작업을 수행하기 위한 Q-값입니다.
- $ {{r}} $는 행동을 취한 후 받는 보상입니다.
- $ {{\ gamma}} $는 향후 보상의 중요성을 결정하는 할인 요소입니다.
- $ {{\ max_ {a'} Q (s', a')}} $는 가능한 모든 작업 $ {{a'}} $에 대한 다음 상태의 최대 Q-값입니다. $ {{a'}} $.
시간적 차이 학습
시간차 (TD) 학습은 동적 프로그래밍과 몬테카를로 방법에서 얻은 아이디어를 결합하는 RL의 핵심 접근 방식입니다.예측값과 실제 받은 보상 간의 차이 (또는 시간적 차이) 에 다음 상태의 할인가를 더한 값을 기반으로 값 함수를 업데이트합니다.
TD 학습의 일종인 Q-러닝의 업데이트 규칙은 다음과 같습니다.
$$ {{Q (s, a)\ 왼쪽화살표 Q (s, a) +\ 알파\ 왼쪽 (r +\ gamma\ max_ {a'} Q (s', a') - Q (s, a)\ 오른쪽)}} $$
여기:
- $ {{\ alpha}} $는 새로운 정보가 이전 정보보다 우선하는 정도를 제어하는 학습률입니다.
- $ {{r+γ\ max_ {a'} Q (s', a')}} $는 즉각적인 보상과 예상 미래 보상을 합한 현재 Q-값의 목표값입니다.
강화 학습은 복잡한 의사 결정 문제를 해결하기 위한 강력한 프레임워크입니다.이 프레임워크는 환경과의 시행착오 상호작용을 통해 최적의 전략을 학습합니다.
DQN 작동 방식:
딥 Q-네트워크 (DQN) 는 Q-러닝을 심층 신경망과 결합하여 다양한 상태와 동작이 있는 환경을 처리합니다.
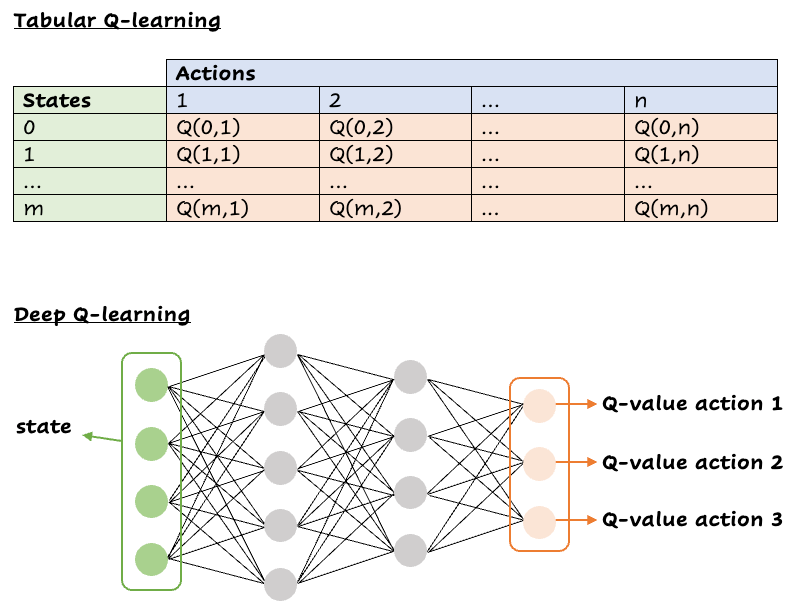
경험을 통한 학습
Q-러닝은 에이전트가 환경과의 상호작용을 통해 보상을 극대화하는 방법을 학습하는 강화 학습 알고리즘입니다.Q-함수 Q (s, a) 를 사용하여 미래 보상을 예측합니다.에이전트는 Bellman 방정식을 사용하여 Q-값을 업데이트하고, 받은 보상과 예상 미래 보상을 기반으로 예측을 조정합니다.
실무 사례
예측된 Q (s, a) = 100인 sss 상태에 있다고 상상해 보십시오.행동 a를 수행한 후 '상태로 전환하고 8의 보상을 받습니다.s에서 가장 좋은 액션에 대한 Q-값은 95이고 할인율은 0.99입니다.시간적 차이는 $ {8 + 0.99\ 곱하기 95 - 100 = 2.05}} $입니다.학습률이 0.1인 경우 업데이트된 Q-값은 $ {100 + 0.1\ 곱하기 2.05= 100.205}} $가 됩니다.
딥 Q-러닝
기존의 Q-러닝은 테이블을 사용하여 Q-값을 저장하는데, 이는 상태와 동작이 많은 환경에서는 불가능합니다.DQN은 신경망을 사용하여 Q (s, a) 의 근사치를 구하므로 에이전트는 보이지 않는 상태-동작 쌍으로 일반화할 수 있습니다.신경망의 입력값은 관측값이고 출력값은 가능한 각 동작에 대한 Q-값입니다.
DQN 알고리즘
- 익스피리언스 리플레이: 경험 (s, a, r, s') 을 리플레이 버퍼에 저장합니다.버퍼에서 무작위로 샘플링하면 시간적 상관관계를 깨뜨려 학습의 안정성을 높일 수 있습니다.
- 대상 네트워크: 의사 결정을 위한 기본 네트워크와 안정적인 Q-값 목표를 제공하기 위한 대상 네트워크라는 두 개의 신경망을 사용합니다.
- 교육 단계:
리플레이 버퍼와 네트워크를 초기화합니다.
각 에피소드마다:
시작 상태를 초기화합니다.
각 단계마다:
- \ epsilon-욕심 정책을 사용하여 작업 aaa를 선택합니다.
- 작업을 실행하고 보상 r과 다음 상태 s를 관찰합니다.
- 리플레이 버퍼에 경험을 저장합니다.
- 리플레이 버퍼에서 미니 배치를 샘플링합니다.
- 목표 Q-값을 계산하고 손실에 대한 경사하강법을 수행합니다.
- 대상 네트워크를 정기적으로 업데이트하십시오.
안정성을 위한 개선 사항
안정성과 융합을 보장하기 위해 몇 가지 개선 사항이 구현되었습니다.
- e-그리디 액션 셀렉션: 시간이 지남에 따라 탐색 속도를 조정하여 탐색과 착취의 균형을 유지합니다.
- 익스피리언스 리플레이: 과거의 경험을 바탕으로 학습할 수 있으므로 안정적인 교육과 더 나은 융합이 보장됩니다.
- 대상 네트워크 vs. 로컬 네트워크: 목표 네트워크를 사용하여 안정적인 Q-값 목표를 제공하여 진동과 발산을 줄입니다.
대상 네트워크 vs. 로컬 네트워크
DQN에서는 학습을 안정화하기 위해 두 개의 네트워크가 사용됩니다.
- 기본 (로컬) 네트워크: 이 네트워크는 지속적으로 업데이트되며 훈련 중 동작을 선택하는 데 사용됩니다.예측된 Q-값과 목표 Q-값 간의 손실을 최소화하여 학습합니다.
- 대상 네트워크: 이 네트워크는 Q-값 업데이트의 안정적인 대상을 제공합니다.기본 네트워크와 달리 대상 네트워크의 가중치는 일반적으로 수천 단계마다 기본 네트워크의 가중치를 복사하여 업데이트되는 빈도가 낮습니다.
왜 두 개의 네트워크를 사용할까요?
- 안정성: 기본 네트워크의 가중치가 자주 업데이트되므로 불안정성과 격차가 발생할 수 있습니다.목표 네트워크를 사용하여 안정적인 Q-값 목표값을 제공함으로써 학습의 급격한 변동을 피할 수 있습니다.
- 일관성: 목표 네트워크는 주기적으로만 업데이트되므로 일관된 학습 목표를 유지하는 데 도움이 됩니다.따라서 Q-값 업데이트는 보다 안정적이고 신뢰할 수 있는 목표를 기반으로 하므로 학습이 더 원활하고 안정적입니다.
업데이트 메커니즘
- 기본 네트워크 업데이트: 각 동작 후에 기본 네트워크는 대상 네트워크에서 제공한 예측된 Q-값과 목표 Q-값 간의 차이에서 계산된 손실을 사용하여 가중치를 업데이트합니다.
- 타겟 네트워크 업데이트: 수천 단계마다 기본 네트워크의 가중치가 대상 네트워크에 복사되므로 대상 네트워크가 일정 단계 동안 안정적인 대상을 제공한 후 다시 업데이트됩니다.
다음은 자세한 코드 예제입니다.
1단계: 필수 라이브러리 설치
1pip install gymnasium gymnasium[box2d] stable-baselines3 torch2단계: 라이브러리 및 설정 환경 가져오기
1import gym
2from stable_baselines3 import DQN
3from stable_baselines3.common.evaluation
4import evaluate_policy
5
6# Create the Lunar Lander environment
7env = gym.make("LunarLander-v2")3단계: DQN 모델 정의
1# Define the DQN model
2model = DQN("MlpPolicy", env, verbose=1)4단계: DQN 모델 학습
1# Train the model
2model.learn(total_timesteps=100000) # Adjust the timesteps as needed5단계: 학습된 모델 평가
1# Evaluate the trained mode
2lmean_reward, std_reward = evaluate_policy(model, env, n_eval_episodes=10)
3print(f"Mean reward: {mean_reward} +/- {std_reward}")
4
5# Optionally, save the model
6model.save("dqn_lunar_lander")6단계: 학습된 모델 시각화
1import time
2# Load the model if needed
3# model = DQN.load("dqn_lunar_lander")
4# Visualize the model's performanceepisodes = 5
5
6for episode in range(1, episodes + 1):
7 obs = env.reset()
8 done = False
9 score = 0
10 while not done:
11 env.render()
12 action, _states = model.predict(obs)
13 obs, reward, done, info = env.step(action)
14 score += reward
15 print(f"Episode: {episode}, Score: {score}")
16 time.sleep(1)
17env.close()설명
- 환경 설정: `gym.make (“루나랜더-v3") `는 달 착륙선 환경을 초기화합니다.
- DQN 모델: 스테이블 베이스라인3의 `DQN` 클래스는 MLP 정책으로 모델을 정의하는 데 사용됩니다.
- 훈련: `learn` 메서드는 지정된 수의 타임스텝으로 모델을 훈련시킵니다.
- 평가: `valuate_policy` 함수는 여러 에피소드에 걸쳐 모델의 성능을 평가합니다.
- 시각화: 루프는 환경을 렌더링하여 학습된 모델의 성능을 실시간으로 시각화합니다.
추가 팁
- 하이퍼 파라미터: 성능 향상을 위해 하이퍼 파라미터 (예: 학습률, 배치 크기 등) 를 조정해야 할 수 있습니다.
- 체크포인팅: 학습 중에 중간 모델을 저장하여 진행 상황이 손실되지 않도록 합니다.
- 모니터링: TensorBoard를 사용하여 교육 메트릭을 실시간으로 모니터링하세요.
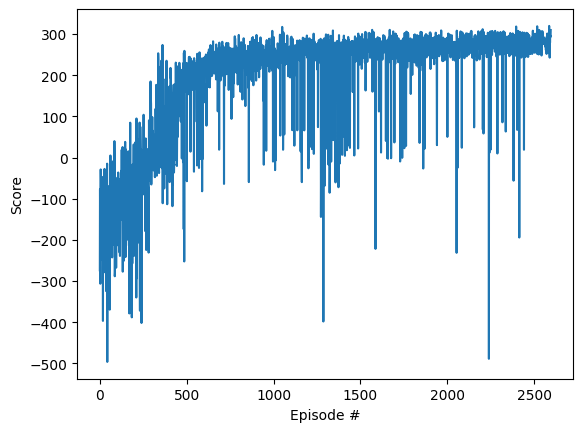
.gif)
결론
DQN은 Q-러닝과 심층 신경망을 결합한 강력한 강화 학습 알고리즘입니다.DQN은 경험 리플레이 및 목표 네트워크와 같은 기술을 활용하여 Gymnum의 Lunar Lander와 같은 복잡한 환경을 해결하는 방법을 효과적으로 학습하여 게임 및 실제 애플리케이션 모두에서 그 잠재력을 입증합니다.대상 네트워크를 기본 네트워크와 함께 사용하면 학습의 안정성과 일관성이 보장되므로 DQN은 광범위한 RL 문제에 대한 강력하고 효율적인 알고리즘이 됩니다.
비용 및 실행 시간
이것은 구글 콜랩 프로 GPU T4를 사용하여 학습되었습니다.
추가 학습 자료
- DQN을 이용한 딥 Q 러닝 - 강화 학습 p.5
- 로켓 착륙을 위한 AI 학습 (달 착륙선) | 강화 학습
- 체육관 문서 - 루나 랜더
- 심층 강화 학습으로 Atari 플레이하기
- 케라스와 함께 DQN을 이용한 달 착륙선 문제 해결
- 딥 Q-네트웍스 설명
- BCS 멤버 그룹 - 딥 Q 네트워크 DQN
- 유다시티 - 심층 강화 학습


