소개
끊임없이 진화하는 인공 지능 세계에서 강화 (RL) 환경에서 복잡한 의사 결정을 내리도록 강력한 의사 결정을 도와주세요.RL 분야에서 가장 어려운 과제 중 하나는 Gyum의 카레이싱 환경입니다.환경은 레이스 에이전트가 효율적으로 ########################## ##### ### #### #### ### #### ### ###### ###
이 블로그 게시물에서는 세 가지 주요 RL 알고리즘인 소프트 액터-크리틱 (SAC), 근위 최적화 정책 (PPO), 딥 큐네트워크 (DQN) 를 레이싱 사용하여 환경을 구축하는 방법을 자세히 살펴보겠습니다.알고리즘은 고유의 강점과 각각 약점을 가지고 함께할 수 있습니다.
각 알고리즘의 이론적 토대를 주의, 구현에 대해 논의하고, 카레이싱 환경에서의 성능을 분석해 보세요.이 여정을 마치면 각 접근 방식의 배려에 대한 통찰력을 얻을 수 있습니다.노련한 RL 초급자만과 관계없이 이 강화 탐색을 위한 심칠 수 있습니다.
자동차 경주 및 보수
Carracing-v3 환경은 에이전트가 단계적으로 생성된 경마장에서 제어 작업을 수행합니다.목표는 트랙 주위를 최대한 효율적으로 트랙하여 시간을 최소화할 수 있는 타일 수를 최대화하는 것입니다.이 상태 및 연재하기 어려운 환경은 문제를 추적할 수 있습니다.
Carracing-v3의 보상 시스템은 주로 에이전트가 ######### #2 ## #2 ##### #2 #################################################################################################################################################################################################################################### #벗어나는 시간을 최대한 활용할 수 있도록 도와주세요. #1 #1 #0 #각 #트랙을
근위 정책 최적화 (팝)
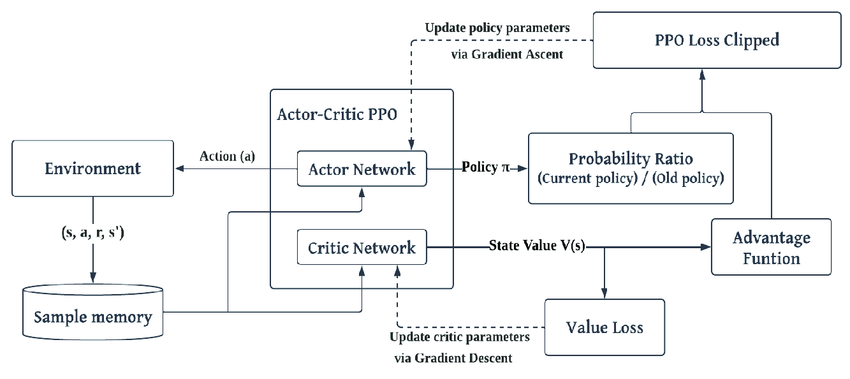
PO는 TRPO와 같은 알고리즘에 대한 신뢰 영역 최적화를 실현하는 온-정책 알고리즘입니다. 특히 작업 공간이 연속적인 환경에서 안정성과 견고성을 유지하는 것이 잘 이루어질 수 있습니다.
해결:
1import gymnasium as gym
2from stable_baselines3 import PPO
3
4# Create CarRacing environment
5env = gym.make('CarRacing-v3')
6
7# Initialize PPOmodel = PPO('CnnPolicy', env, verbose=1)
8
9# Train the model
10model.learn(total_timesteps=1000000)
11
12# Save the model
13model.save("ppo_car_racing")자동차 경주에서의 성능:
- 강점: PPO는 교육을 가난하게 만들 수 있는 것은 급격한 변화를 피하면서 정책을 점진적으로 조정할 수 있기 때문에 카레이와 같은 지속적인 활동 환경에서 잘 작동합니다.
- 약점: PPO는 온폴리시 알고리즘이기 때문에 SAC와 같은 정책 외 방법에 더 많은 데이터를 필요로 하며 샘플 효율성이 떨어질 수 있습니다.
팝 실무 사례:
카 레이싱에서 PPO는 탐험과 착취의 균형을 유지합니다.PPPO의 클리핑 메커니즘은 대규모 정책 업데이트를 통해 안정되고 안정적인 제어가 환경에 필요합니다.
소프트 액터-크리틱 (SAC)
<엔트로피 최대화와 행위자-비평가 프레임워크를 다룬 #오프 정책, 에이전트가 학습하는 것은 최대한 무작위로 행동하도록 장려하여 탐색을 한다.
해결:
1import gymnasium as gym
2from stable_baselines3 import SAC
3
4# Create CarRacing environment
5env = gym.make('CarRacing-v3')
6
7# Initialize SAC
8model = SAC('CnnPolicy', env, verbose=1)
9
10# Train the model
11model.learn(total_timesteps=1000000)
12
13# Save the model
14model.save("sac_car_racing")자동차 경주에서의 성능:
- 강점: SAC는 샘플 효율성이 매우 높아 동작이 연속적이고 정밀한 제어가 필요한 카레이싱과 같은 환경에 적합합니다.
- 약점: 알고리즘은 구현하기가 더 복잡하며 특히 탐색과 활용의 균형을 맞추는 온도계 | 파라미터 | 세심한 조정이 필요합니다.
실제 주머니:
카레이싱 삭의 엔트로피 기반 탐색은 에이전트가 다양한 전략을 발견하고 트랙의 변화에 적응하는 데 도움이 됩니다.고차원 공간을 탐색하는 데 도움이 됩니다.
딥 Q-네트워크 (DQN)
DQN은 RL LAN의 선구적인 알고리즘으로, 특히 개별 동작 공간에서 효과적입니다.신경망을 통한 작용값 추정을 위한 Q-값의 근사치를 구합니다.
해결:
1import gymnasium as gym
2from stable_baselines3 import DQN
3
4# Create CarRacing environment
5env = gym.make('CarRacing-v3')
6
7# Initialize DQN
8model = DQN('CnnPolicy', env, verbose=1)
9
10# Train the model
11model.learn(total_timesteps=1000000)
12
13# Save the model
14model.save("dqn_car_racing")자동차 경주에서의 성능:
- 강점: DQN은 상대적으로 계산이 적은 개별 작업이 가능한 환경에서 간단하고 효율적입니다.
- 약점: 카 레이싱과 같은 연속적인 액션 공간에는 적합합니다.액션의 따뜻함이 필요하면 게임이 최적화되지 않고 성능이 저하될 수 있습니다.
실제 이름:
DQN은 아타리와 같은 게임에서 성공을 거둘 수 있고, 카레이싱에서는 지속적인 환경 특성으로 변모할 수 있습니다.액션 또는 공간을 절약하고 접근 방식을 사용하는 등 수정이 필요해요.
알고리즘 비교
팝:
- 강점: 정책 기울기 방식의 지속적인 작업 공간이 있는 환경에서 안정성이 잘 작동합니다.
- 약점: 온폴리시 알고리즘이기 때문에 샘플 효율성이 떨어지고 환경과의 상호 작용이 더 많이 필요할 수 있습니다.
낭:
- 강점: 시료 효율이 매우 높고 연속 작업이 가능한 공간입니다.엔트로피 최대화를 사용하면 강력한 탐색을 할 수 있습니다.
- 약점: 특히 엔트로피 계수와 관련하여 구현 및 조정이 더 복잡합니다.
단:
- 강점: 개별 작업 환경에서의 단순성 및 효율성.일부 정책 기반 방법보다 계산 집약도가 낮습니다.
- 약점: 큰 수정 없이 고차원적이고 연속적인 액션 공간에서 어려움을 겪습니다.
결론
카레이싱 환경에서는 PPO와 SAC가 효과적인 더 선택입니다.SAC의 샘플 효율성과 연속 작업 환경에서의 강력한 성능은 유리합니다.반면, DQN은 개별 공간에서는 강력하면서도 명확한 작업 설계 한계로 이러한 선택을하겠습니다.
요약하면 이러한 알고리즘의 강점과 약점을 이해하면 카레이싱과 같은 복잡한 작업에서 얻을 수 있는 귀중한 통찰력을 얻을 수 있습니다. 올바른 공약을 신중하게 조정하면 까다로운 환경에서 큰 성과를 낼 수 있습니다.
%2520(1).gif)


